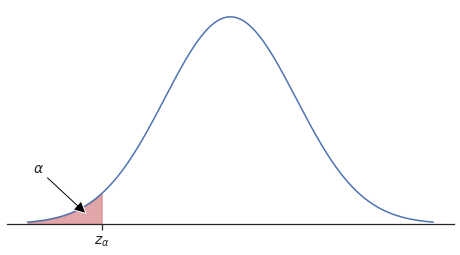
En estudios de inferencia estadística se utiliza mucho la distribución normal estándar, ya sea en los intervalos de confianza o en las pruebas de hipótesis. Los parámetros con los que se trabajan son los valores \(z_\alpha\) y \(\alpha\). Vease la siguiente figura.
z y alfa en la gráfica
Python tiene el módulo scipy.stats.norm que contiene las funciones para determinar estos 2 parámetros: las funciones ppf y cdf. La función cdf se denomina cumulative distribution function, en español, función de distribución acumulada. Mientras la función ppf se denomina percent point function o inverse cumulative distribution function, en español, función de distribución acumulada inversa. Es decir una función es la inversa de la otra, y son conceptos que aparecen cuando estudiamos variables aleatorias y distribuciones de probabilidad.
En su forma matemática cdf, con Z como variable aleatoria, se expresa:
\(f(x)\) es la función de densidad de probabilidad, que en este caso es la normal estándar, y es la que define la forma de campana de la distribución: $$f(x) = \frac{1}{\sqrt{2\pi}} \cdot e ^{-\frac{x^2}{2}}$$
Mientras que ppf sería la inversa:
$$z_\alpha = F_Z^{-1}(\alpha)$$
En definitiva, con la función ppf podemos determinar el valor de \(z_\alpha\) conocido \(\alpha\), y con la función cdf podemos determinar el valor de \(\alpha\) conocido \(z_\alpha\).
Veamos ahora como utilizarlas con el siguiente ejemplo. Supongamos que queremos determinar el valor de z para un \(\alpha\) de 0,025 (\(z_{0,025}\)). El código en Python es:
In:
from scipy import statsalfa= 0.025z_alfa = stats.norm.ppf(alfa)z_alfa
Out:
-1.9599639845400545
Ahora a la inversa, determinar \(\alpha\) para un z de -1.96. Debe dar 0,025 aproximadamente, por lo que decíamos antes, que una es la función inversa de la otra.
In:
from scipy import statsz_alfa= -1.96alfa = stats.norm.cdf(z_alfa)alfa
Out:
0.024997895148220435
Para terminar voy dejar el código para crear el gráfico de la figura anterior. Antes, eso sí, hay que mencionar otra función de este módulo: la función pdf. Esta función permite obtener los valores de la función de densidad dado un valor z. De este modo obtendríamos una tabla de datos para poder graficar. En el código siguiente fijarse en la definición de f_x = lambda x: stats.norm.pdf(x) que es la función de densidad para la normal estándar. Luego esta misma función f_x se usa para crear la gráfica en ax.plot(x, f_x(x)).
In:
from scipy import statsimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snssns.set_theme(style="ticks")#Distribución normal estándar: dominio x y función de densidad de probabilidad f(x)x_inf = stats.norm.ppf(0.001)x_sup = stats.norm.ppf(0.999)x = np.linspace(x_inf, x_sup, 10000)f_x = lambdax: stats.norm.pdf(x)#Alfa y zz_alfa = -1.96x_z = np.linspace(x_inf, z_alfa,10000)#Creación de gráficofig, ax = plt.subplots(figsize=(8,4))ax.plot(x, f_x(x))ax.fill_between(x_z, y1=f_x(x_z), y2=0, color="r", alpha=0.5)#--Anotación en gráficoax.annotate(r"$\alpha$",xy=(-2.2,0.02),xytext=(-3,0.1),arrowprops=dict(facecolor='black', width=2),fontsize=14)#--Personalizando gráficoax.spines[['left', 'top','right']].set_visible(False)plt.ylim(bottom=0)plt.yticks([])plt.xticks(ticks= [z_alfa], labels=[r"$z_\alpha$"], fontsize=14)plt.show()